
Neural Networks
Neural networks are a class of models that are built with layers. Commonly used types of neural networks include convolutional and recurrent neural networks.
Architecture ― The vocabulary around neural networks architectures is described in the figure below:
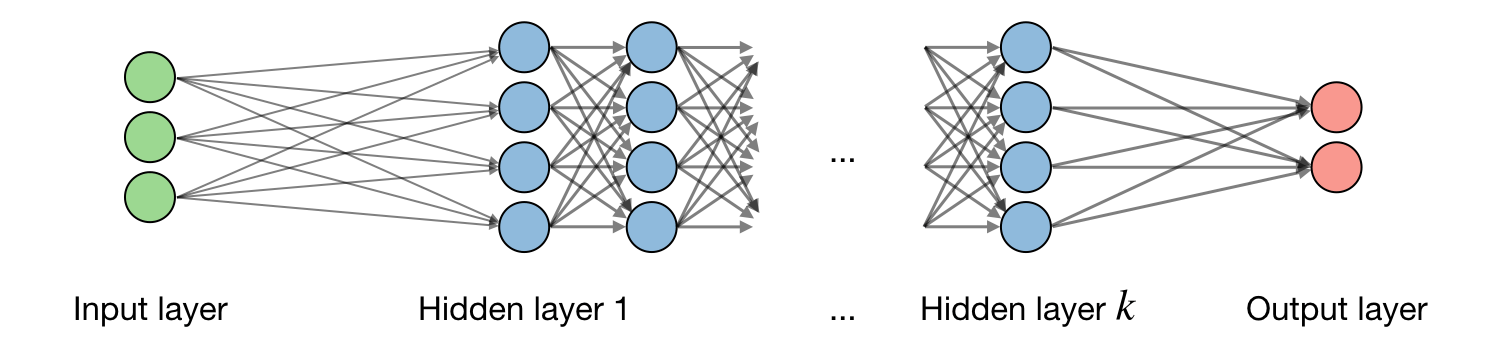
By noting the layer of the network and the hidden unit of the layer, we have:
where we note , , the weight, bias and output respectively.
Activation function ― Activation functions are used at the end of a hidden unit to introduce non-linear complexities to the model. Here are the most common ones:
| Sigmoid | Tanh | ReLU | Leaky ReLU |
with | |||
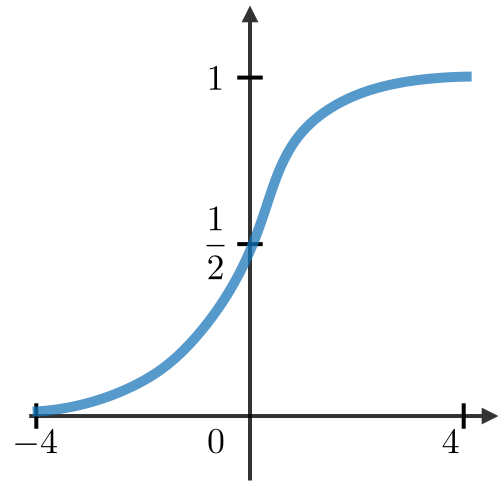 | 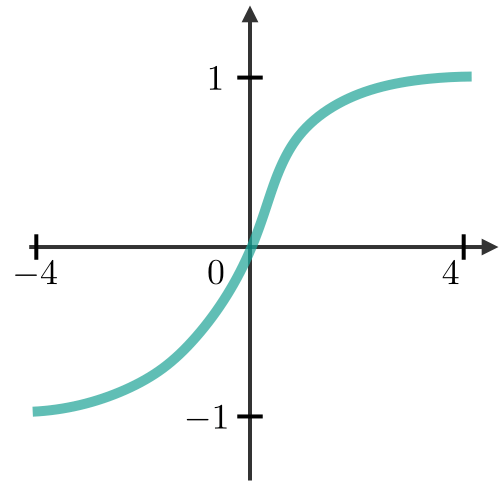 | 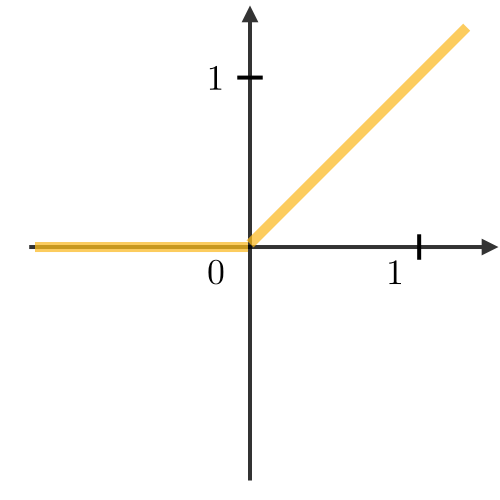 | 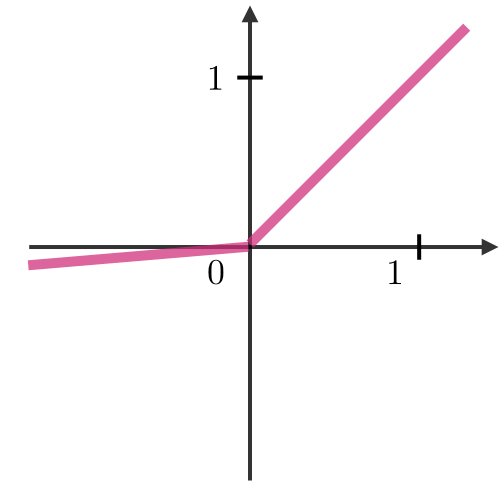 |
Cross-entropy loss ― In the context of neural networks, the cross-entropy loss is commonly used and is defined as follows:
Learning rate ― The learning rate, often noted or sometimes , indicates at which pace the weights get updated. This can be fixed or adaptively changed. The current most popular method is called Adam, which is a method that adapts the learning rate.
Backpropagation ― Backpropagation is a method to update the weights in the neural network by taking into account the actual output and the desired output. The derivative with respect to weight is computed using chain rule and is of the following form:
As a result, the weight is updated as follows:
Updating weights ― In a neural network, weights are updated as follows:
- Step 1: Take a batch of training data.
- Step 2: Perform forward propagation to obtain the corresponding loss.
- Step 3: Backpropagate the loss to get the gradients.
- Step 4: Use the gradients to update the weights of the network.
Dropout ― Dropout is a technique meant at preventing overfitting the training data by dropping out units in a neural network. In practice, neurons are either dropped with probability or kept with probability
Convolutional Neural Networks
Convolutional layer requirement ― By noting the input volume size, the size of the convolutional layer neurons, the amount of zero padding, then the number of neurons that fit in a given volume is such that:
Batch normalization ― It is a step of hyperparameter that normalizes the batch . By noting the mean and variance of that we want to correct to the batch, it is done as follows:
Recurrent Neural Networks
Types of gates ― Here are the different types of gates that we encounter in a typical recurrent neural network:
| Input gate | Forget gate | Gate | Output gate |
| Write to cell or not? | Erase a cell or not? | How much to write to cell? | How much to reveal cell? |
LSTM ― A long short-term memory (LSTM) network is a type of RNN model that avoids the vanishing gradient problem by adding 'forget' gates.
For a more detailed overview of the concepts above, check out the Deep Learning cheatsheets!
Reinforcement Learning and Control
The goal of reinforcement learning is for an agent to learn how to evolve in an environment.
Definitions
Markov decision processes ― A Markov decision process (MDP) is a 5-tuple where:
- is the set of states
- is the set of actions
- are the state transition probabilities for and
- is the discount factor
- or is the reward function that the algorithm wants to maximize
Policy ― A policy is a function that maps states to actions.
Remark: we say that we execute a given policy if given a state we take the action .
Value function ― For a given policy and a given state , we define the value function as follows:
Bellman equation ― The optimal Bellman equations characterizes the value function of the optimal policy :
Remark: we note that the optimal policy for a given state is such that:
Value iteration algorithm ― The value iteration algorithm is in two steps:
1) We initialize the value:
2) We iterate the value based on the values before:
Maximum likelihood estimate ― The maximum likelihood estimates for the state transition probabilities are as follows:
Q-learning ― -learning is a model-free estimation of , which is done as follows:




0 Comments